Hi @ajcwebdev. Curious how Fauna + RW is working out?
I’ve given Fauna some thoughts and wonder if you have had the same.
RW’s web side talks to the api side over graphql. Cool.
The api side can talk to datastores via services + sdl. Also cool.
Out of the box, Prisma is supported since there is a readily available db client to import and write queries/mutations.
But, a service is a service. My SDL can define the queries, but I don’t have to use the Prisma db client. I could use the Contentful SDK – or call another graphql endpoint (Hasura … or Fauna … or Contentful for that matter) using graphql-request.
I’ve shared this example here before, but my I made an app a year or so ago where 8 year old niece uses Contentful to keep track of little Disney Princess cupcake characters she build from pieces of a board game. The SDL is:
import gql from 'graphql-tag'
export const schema = gql`
type Cupcake {
id: String!
name: String!
description: String!
price: Float
rating: Int
slug: String!
photos: [ContentfulAsset]
}
type Query {
cupcakes: [Cupcake!]!
cupcake(id: String!): Cupcake!
}
`
and the service that uses their SDK is:
import { createClient } from 'contentful'
const client = createClient({
space: process.env.CONTENTFUL_SPACE,
accessToken: process.env.CONTENTFUL_DELIVERY_API_KEY,
})
const renderAsset = (fields) => {
return { title: fields.title, file: fields.file }
}
const renderAssets = (assets) => {
return assets.map((asset) => renderAsset(asset.fields))
}
const renderEntry = (entry) => {
return {
id: entry.sys.id,
name: entry.fields.name,
description: entry.fields.description,
price: entry.fields.price,
rating: entry.fields.rating,
slug: entry.fields.slug,
photos: renderAssets(entry.fields.photos),
}
}
export const cupcakes = async () => {
const response = await client.getEntries({
content_type: 'cupcake',
limit: 1000,
order: 'fields.name',
})
return response.items.map((entry) => renderEntry(entry))
}
export const cupcake = async ({ id }) => {
const entry = await client.getEntry(id)
return renderEntry(entry)
}
and then I can use RW cells just as I would if I was querying a Prisma Postgres database:
import Cupcake from 'src/components/Cupcake'
export const QUERY = gql`
query {
cupcakes {
id
name
description
price
rating
slug
photos {
title
file {
url
}
}
}
}
`
export const Loading = () => {
return (
<Stack>
<Box mb={6} maxW="sm" overflow="hidden">
<Box p="6">
<Skeleton height="20px" my="10px" />
</Box>
</Box>
<Box mb={6} maxW="sm" overflow="hidden">
<Box p="6">
<Skeleton height="20px" my="10px" />
</Box>
</Box>
<Box mb={6} maxW="sm" overflow="hidden">
<Box p="6">
<Skeleton height="20px" my="10px" />
</Box>
</Box>
</Stack>
)
}
export const Empty = () => <div>Empty</div>
export const Failure = ({ error }) => <div>Error: {error.message}</div>
export const Success = ({ cupcakes }) => {
return cupcakes.map((cupcake) => (
<Cupcake key={cupcake.id} cupcake={cupcake}></Cupcake>
))
}
Or, if I wanted to call another GraphQL endpoint, in this case a PG-backed view served by Hasura for “daily story counts” my SDL is:
import gql from 'graphql-tag'
export const schema = gql`
type Calendar {
day: String!
value: Int!
}
type Query {
dailyStoryCounts: [Calendar!]!
}
`
I then have a Hasura client (just like a lib/db)
import { GraphQLClient } from 'graphql-request'
export const request = async (
query = {},
domain = process.env.HASURA_DOMAIN
) => {
const endpoint = `https://${domain}/v1/graphql`
const graphQLClient = new GraphQLClient(endpoint, {
headers: {
'x-hasura-admin-secret': process.env.HASURA_KEY,
},
})
try {
return await graphQLClient.request(query)
} catch (error) {
console.log(error)
return error
}
}
Then my service uses that client to fetch:
import { request } from 'src/lib/hasuraClient'
export const dailyStoryCounts = async () => {
const query = `
{
dailyStoryCounts: calendar {
day: date
value
}
}
`
const data = await request(query, process.env.HASURA_DOMAIN)
return data['dailyStoryCounts']
}
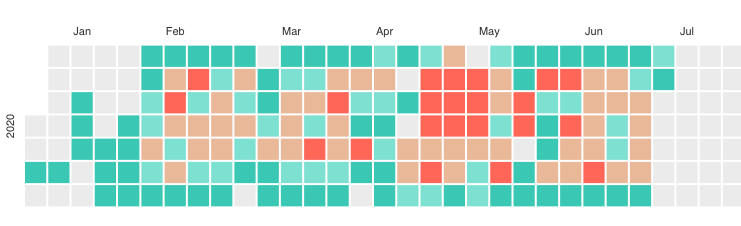
and my cells is normal and can render a nice calendar chart:
import { Box } from '@chakra-ui/core'
import { ResponsiveCalendar } from '@nivo/calendar'
export const QUERY = gql`
query {
dailyStoryCounts {
day
value
}
}
`
export const Loading = () => <div>Loading...</div>
export const Empty = () => <div>Empty</div>
export const Failure = ({ error }) => <div>Error: {error.message}</div>
export const Success = ({ dailyStoryCounts }) => {
const firstDay = dailyStoryCounts[0].day
const lastDay = dailyStoryCounts[dailyStoryCounts.length - 1].day
return (
<Box height="600px" width="100%">
<ResponsiveCalendar
data={dailyStoryCounts}
from={firstDay}
to={lastDay}
emptyColor="#eeeeee"
colors={['#61cdbb', '#97e3d5', '#e8c1a0', '#f47560']}
margin={{ top: 40, right: 40, bottom: 40, left: 40 }}
yearSpacing={40}
monthBorderColor="#ffffff"
dayBorderWidth={2}
dayBorderColor="#ffffff"
legends={[
{
anchor: 'bottom-right',
direction: 'row',
translateY: 36,
itemCount: 4,
itemWidth: 42,
itemHeight: 36,
itemsSpacing: 14,
itemDirection: 'right-to-left',
},
]}
/>
</Box>
)
}
(note: I turned off data in July)
Ok. That was long winded, I know.
But, to implement Fauna right now I would either:
- use the Fauna client and write FQL (ie, the Contentful SDK approach)
- make a gql client and write graphql against Fauna (the Hasura approach)
What I don’t think I would want is for the web to call Fauna directly or RW’s graphql to somehow relay the gql to Fauna. Do I? Don’t think so, but I have not experimented.
But what I think is super super cool is that I think if I had services that talked to Contentful (cupcakes) and Hasura (stories) and Prisma/Postgres (users), I am pretty sure I could make a single graphql request from a cell like
query {
cupcakes {
id
name
}
stories {
id
title
}
users {
id
email
}
}
And I could render all the data from three different sources in a Dashboard cell like:
export const Success = ({ cupcakes, stories, users }) => {
}
And if the id’s somehow matched, I could probably even filter: give me stories this user wrote about these cupcakes.
That’s really really cool.
BTW - this is Monty: “Monty likes to play in the woods to hide from his sister Minty.”

 You just need to manually write the SDL and service functions.
You just need to manually write the SDL and service functions.


 and Citus mentions it as their preferred connection pooler
and Citus mentions it as their preferred connection pooler